When it comes to APIs, change isn’t popular. While software developers are used to iterating quickly and often, API developers lose that flexibility as soon as even one user starts consuming their interface. Many of us are familiar with how the Unix operating system evolved. In 1994, The Unix-Haters Handbookwas published containing a long list of missives about the software—everything from overly-cryptic command names that were optimized for Teletype machines, to irreversible file deletion, to unintuitive programs with far too many options. Over twenty years later, an overwhelming majority of these complaints are still valid even across the dozens of modern derivatives. Unix had become so widely used that changing its behavior would have challenging implications. For better or worse, it established a contract with its users that defined how Unix interfaces behave.
Similarly, an API represents a contract for communication that can’t be changed without considerable cooperation and effort. Because so many businesses rely on Stripe as infrastructure, we’ve been thinking about these contracts since Stripe started. To date, we’ve maintained compatibility with every version of our API since the company’s inception in 2011. In this article, we’d like to share how we manage API versions at Stripe.
Code written to integrate with an API has certain inherent expectations built into it. If an endpoint returns a boolean field called verified to indicate the status of a bank account, a user might write code like this:
if bank_account[:verified]
...
else
...
end
If we later replaced the bank account’s verified boolean with a status field that might include the value verified (like we did back in 2014), the code will break because it depends on a field that no longer exists. This type of change is backwards-incompatible, and we avoid making them. Fields that were present before should stay present, and fields should always preserve their same type and name. Not all changes are backwards-incompatible though; for example, it’s safe to add a new API endpoint, or a new field to an existing API endpoint that was never present before.
With enough coordination, we might be able to keep users apprised of changes that we’re about to make and have them update their integrations, but even if that were possible, it wouldn’t be very user-friendly. Like a connected power grid or water supply, after hooking it up, an API should run without interruption for as long as possible.
Our mission at Stripe is to provide the economic infrastructure for the internet. Just like a power company shouldn’t change its voltage every two years, we believe that our users should be able to trust that a web API will be as stable as possible.
API versioning schemes
A common approach to allow forward progress in web APIs is to use versioning. Users specify a version when they make requests and API providers can make the changes they want for their next version while maintaining compatibility in the current one. As new versions are released, users can upgrade when it’s convenient for them.
This is often seen as a major versioning scheme with names like v1, v2, and v3that are passed as a prefix to a URL (like /v1/widgets) or through an HTTP header like Accept. This can work, but has the major downside of changes between versions being so big and so impactful for users that it’s almost as painful as re-integrating from scratch. It’s also not a clear win because there will be a class of users that are unwilling or unable to upgrade and get trapped on old API versions. Providers then have to make the difficult choice between retiring API versions and by extension cutting those users off, or maintaining the old versions forever at considerable cost. While having providers maintain old versions might seem at first glance to be beneficial to users, they’re also paying indirectly in the form of reduced progress on improvements. Instead of working on new features, engineering time is diverted to maintaining old code.
At Stripe, we implement versioning with rolling versions that are named with the date they’re released (for example, 2017-05-24). Although backwards-incompatible, each one contains a small set of changes that make incremental upgrades relatively easy so that integrations can stay current.
The first time a user makes an API request, their account is automatically pinned to the most recent version available, and from then on, every API call they make is assigned that version implicitly. This approach guarantees that users don’t accidentally receive a breaking change and makes initial integration less painful by reducing the amount of necessary configuration. Users can override the version of any single request by manually setting the Stripe-Version header, or upgrade their account’s pinned version from Stripe’s dashboard.
Some readers might have already noticed that the Stripe API also defines major versions using a prefixed path (like /v1/charges). Although we reserve the right to make use of this at some point, it’s not likely to change for some time. As noted above, major version changes tend to make upgrades painful, and it’s hard for us to imagine an API redesign that’s important enough to justify this level of user impact. Our current approach has been sufficient for almost a hundred backwards-incompatible upgrades over the past six years.
Versioning under the hood
Versioning is always a compromise between improving developer experience and the additional burden of maintaining old versions. We strive to achieve the former while minimizing the cost of the latter, and have implemented a versioning system to help us with it. Let’s take a quick look at how it works. Every possible response from the Stripe API is codified by a class that we call an API resource. API resources define their possible fields using a DSL:
class ChargeAPIResource
required :id, String
required :amount, Integer
end
API resources are written so that the structure they describe is what we’d expect back from the current version of the API. When we need to make a backwards-incompatible change, we encapsulate it in a version change module which defines documentation about the change, a transformation, and the set of API resource types that are eligible to be modified:
class CollapseEventRequest < AbstractVersionChange
description \
"Event objects (and webhooks) will now render " \
"`request` subobject that contains a request ID " \
"and idempotency key instead of just a string " \
"request ID."
response EventAPIResource do
change :request, type_old: String, type_new: Hash
run do |data|
data.merge(:request => data[:request][:id])
end
end
end
Elsewhere, version changes are assigned to a corresponding API version in a master list:
Version changes are written so that they expect to be automatically applied backwards from the current API version and in order. Each version change assumes that although newer changes may exist in front of them, the data they receive will look the same as when they were originally written.
When generating a response, the API initially formats data by describing an API resource at the current version, then determines a target API version from one of:
A Stripe-Version header if one was supplied.
The version of an authorized OAuth application if the request is made on the user’s behalf.
The user’s pinned version, which is set on their very first request to Stripe.
It then walks back through time and applies each version change module that finds along the way until that target version is reached.
Requests are processed by version change modules before returning a response.
Version change modules keep older API versions abstracted out of core code paths. Developers can largely avoid thinking about them while they’re building new products.
Changes with side effects
Most of our backwards-incompatible API changes will modify a response, but that’s not always the case. Sometimes a more complicated change is necessary which leaks out of the module that defines it. We assign these modules a has_side_effects annotation and the transformation they define becomes a no-op:
class LegacyTransfers < AbstractVersionChange
description "..."
has_side_effects
end
Elsewhere in the code a check will be made to see whether they’re active:
VersionChanges.active?(LegacyTransfers)
This reduced encapsulation makes changes with side effects more complex to maintain, so we try to avoid them.
Declarative changes
One advantage of self-contained version change modules is that they can declare documentation describing what fields and resources they affect. We can also reuse this to rapidly provide more helpful information to our users. For example, our API changelog is programmatically generated and receives updates as soon as our services are deployed with a new version.
We also tailor our API reference documentation to specific users. It notices who is logged in and annotates fields based on their account API version. Here, we’re warning the developer that there’s been a backwards-incompatible change in the API since their pinned version. The request field of Event was previously a string, but is now a subobject that also contains an idempotency key (produced by the version change that we showed above):
Our documentation detects the user’s API version and presents relevant warnings.
Minimizing change
Providing extensive backwards compatibility isn’t free; every new version is more code to understand and maintain. We try to keep what we write as clean as possible, but given enough time dozens of checks on version changes that can’t be encapsulated cleanly will be littered throughout the project, making it slower, less readable, and more brittle. We take a few measures to try and avoid incurring this sort of expensive technical debt.
Even with our versioning system available, we do as much as we can to avoid using it by trying to get the design of our APIs right the first time. Outgoing changes are funneled through a lightweight API review process where they’re written up in a brief supporting document and submitted to a mailing list. This gives each proposed change broader visibility throughout the company, and improves the likelihood that we’ll catch errors and inconsistencies before they’re released.
We try to be mindful of balancing stagnation and leverage. Maintaining compatibility is important, but even so, we expect to eventually start retiring our older API versions. Helping users move to newer versions of the API gives them access to new features, and simplifies the foundation that we use to build new features.
Principles of change
The combination of rolling versions and an internal framework to support them has enabled us to onboard vast numbers of users, make enormous changes to our API—all while having minimal impact on existing integrations. The approach is driven by a few principles that we’ve picked up over the years. We think it’s important that API upgrades are:
Lightweight. Make upgrades as cheap as possible (for users and for ourselves).
First-class. Make versioning a first-class concept in your API so that it can be used to keep documentation and tooling accurate and up-to-date, and to generate a changelog automatically.
Fixed-cost. Ensure that old versions add only minimal maintenance cost by tightly encapsulating them in version change modules. Put another way, the less thought that needs to be applied towards old behavior while writing new code, the better.
While we’re excited by the debate and developments around REST vs. GraphQL vs. gRPC, and—more broadly—what the future of web APIs will look like, we expect to continue supporting versioning schemes for a long time to come.
This is the ultimate REST API for Dummies. In order to be able to give you a REST API definition, let’s go shopping. I will use what I call “The Store Metaphor”. This way you will also be able to understand what the hell is Sheetsu as well and how it can help developers out there to keep the quality in their beautiful code while coding less. This is not a REST API tutorial but a simple explanation for people like me who is not a developer but for some crazy reason feels entitled to understanding this mystery. If you code for a living and have always wanted to share your passion with your mom/dad or your girlfriend/boyfriend but was never able to explain it to her, to find the words and the examples they could relate to, this post may be the link. ;)
This post will cover:
What is REST API?
REST API: The Store Metaphor
REST API & Google Spreadsheet
REST API & API: The Difference
What is REST API?
What the hell is a REST API or Restful API? If you are like me, you are thinking the same thing:
I am not an albino living in a cave (so, not a developer)
I have no intention in start developing or coding
All I see below in this image are the cute colors (green matches red, who knew?):
Cute colors some people call code and make money out of it
To sum up, I don’t have time to get into details to create a solution, I just want a solution that is ready for me— that’s it!
But I still consider myself pretty smart and I want to understand at least the basics, right? So first, I go ask the developers I work with @ Sheetsu about the meaning of a REST API:
“ C’mon Nani, it’s so obvious. It’s a programming architectural implementation intended to increase the efficiency of communication in computing systems by making that data available on-demand by sharing references instead of the complete copy of the data itself. ”
Was that even English?
So then I tried to get more info with specific communities, like the awesome guys at Hacker News and Quora but I still was not getting it. So I try to shake it off and go to uncle Google, looking for an answer a normal human being can understand. Google tells me:
“REST stands for REpresentational State Transfer”
“API means Application Programming Interface”
That moment you have no idea what is happening to your life
Well, I did learn something from it all… that maybe I am not as smart as I thought.
But I will not give up!! Steve Jobs fought cancer for years, my poor mother survived 80’s fashion and Britney Spears still has a career after a shaved head, so anything is possible in this world, right?
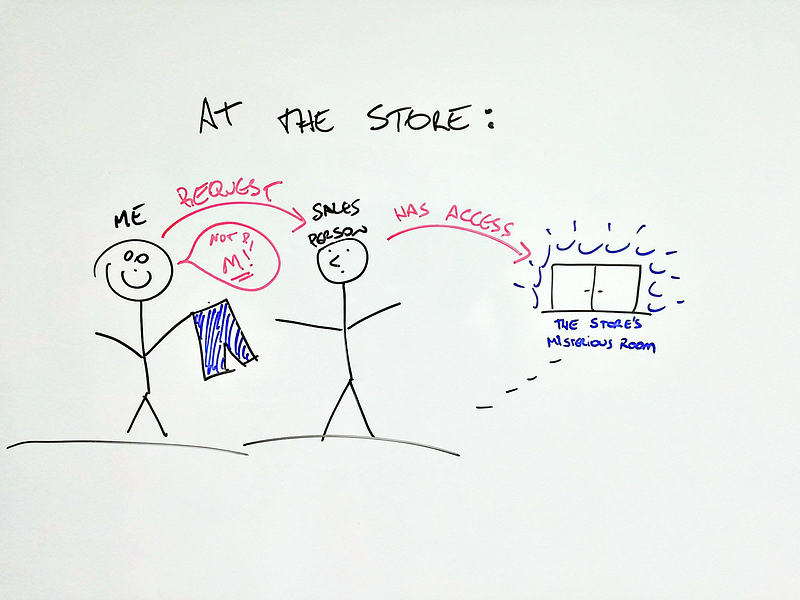
Let’s say you go to your favorite store to buy a new pair of jeans.
You look around and find exactly what you were looking for! But in the wrong size: It’s small while you need medium. But, unless you are a shop lifter, you do not have access to that mysterious room in the back of the store that holds all items they sell, at all sizes and colors.
To get access to this wonderland, you need to make a request to the sales person so you receive back exactly what you need: those pair of jeans you loved, but the right size for you.
You need to make a request to the sales person that has access to that mysterious room in the back of the store
Since the sales person has this special access, he goes inside, gets exactly what you need, comes back and delivers what you requested.
Yes! It’s done!
So let’s Review
In this metaphor, the sales person is the messenger, right? It took a request you made, used the access he had in order to give you what you wanted or at least worked to give you the answer to your question.
Now get ready for this: the sales person is the API!!
Whaaat? Yes!
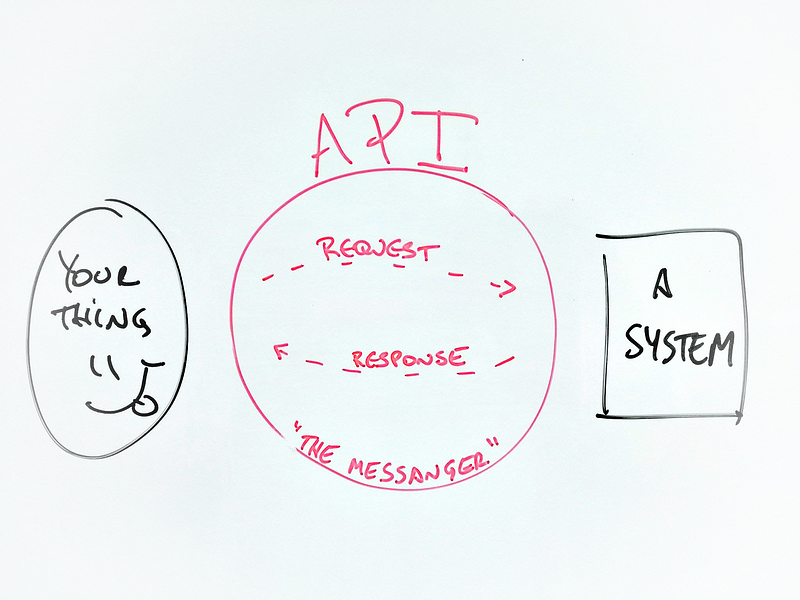
An API is the messenger that takes a request, tells a system what you want to do and then returns the response back to you!
It looks something like this:
An API is the messenger that takes a request, tells a system what you want to do and then returns the response back
… Did I just blow your mind? Let’s get a big deeper than…
REST API & Google Spreadsheet
This is simply the best real-time update you can imagine! Let me explain by going back to the metaphor: let’s say I gained a few pounds.
I tried the pants, size medium, but they didn’t fit. This is our worst nightmare, right? Not only I will have to stop eating chocolate for a while but worst: I will have to find the sales person again!
You guys know what I am talking about. Every single time you look for that freakin’ sales person, they are nowhere to be found! It’s like they disappeared into a dark whole! Then, we always have to stop pause our plans to start a saga to find someone that can help.
At this stage you just want to get the right pants size, pay and leave the store to move on with your life and not waste any more time!
Oh… it would be amazing if we could just type what we needed and the pants you were holding in your hands would magically become your size!
Now let me blow your mind again: THAT IS WHAT SHEETSU DOES!!
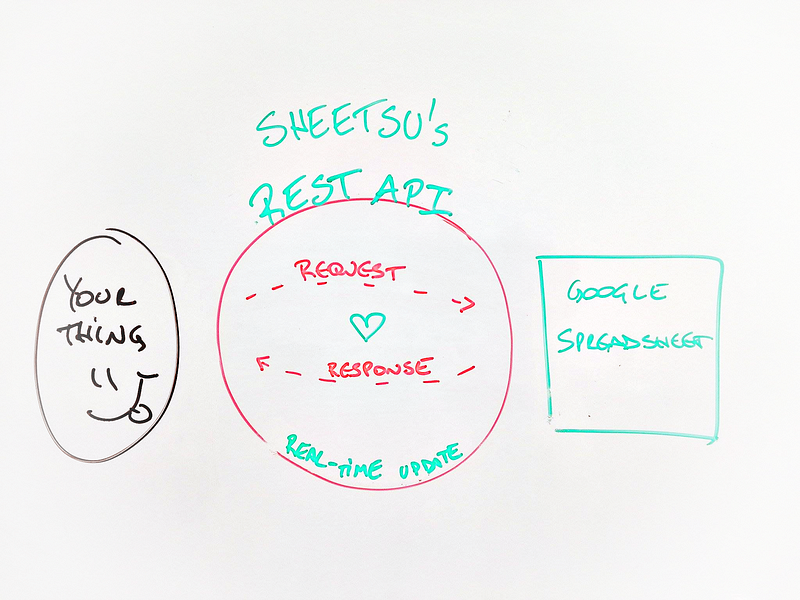
Sheetsu allows you to create a REST API from a Google Spreadsheet. Let’s say it in a different way:Sheetsu turns your Google Spreadsheet into a REST API. Ok, let’s try one more time: Sheetsu connects whatever data you need to a simple Google Spreadsheet in a few steps:
If you use this Sheetsu REST API link to build a website, every time you change something in your spreadsheet, it will automatically change the content on your website too, in real-time! We have “caching” which is a fancy way of saying we will make sure it will all happen fast ;)
It looks a bit like this:
Sheetsu turns your Google Spreadsheet into a REST API
REST API & API: The Difference
Well, to be fair to you, I explained what is an API. So if you ever asks a developer to show you an API or a REST API, that’s all you will see: links. REST is the way you organize these links.
In case you want to find out more about it, I will write a post so you can understand how developers process the same information I gave you on this post. But be careful not to send too many requests because once you get into a black whole… You know what they say…
You may finally find that freaking sales person you were looking for.
When the sales guy shows up last minute for the commission
Well, I hope I was able to truly help you! In case you want to try Sheetsu now, it’s FREE and you can signup using your Google account. If you still have questions, please send me an e-mail to nani@sheetsu.com and I will do an awesome research and write about it ;)
REST wins thanks to the predictability and semantic item. So, is the resource approach better than the operation one?
No.
RPC and REST are only different approaches with pros and cons and both are valueabledepending on the context. You can even mix these two approaches in a single API.
The context, that’s the key. There are no panacea solution, don’t follow fashion blindly, you always have to think within a context and must be pragmatic when choosing a solution.
At least, I know now why I like the resource approach: its predictability and the frame given by the full use of HTTP protocol. What about you?
One last word to leave you with food for thought: in this time of advent of functionnal programming, having operation request style could make sense…
Idempotent Methods and understanding their behavior is critical to getting REST right and nothing explains it better than reading the spec about what it means.
A request method is considered "idempotent" if the intended effect on
the server of multiple identical requests with that method is the
same as the effect for a single such request. Of the request methods
defined by this specification, PUT, DELETE, and safe request methods
are idempotent.